
7 CPU (中央处理器)
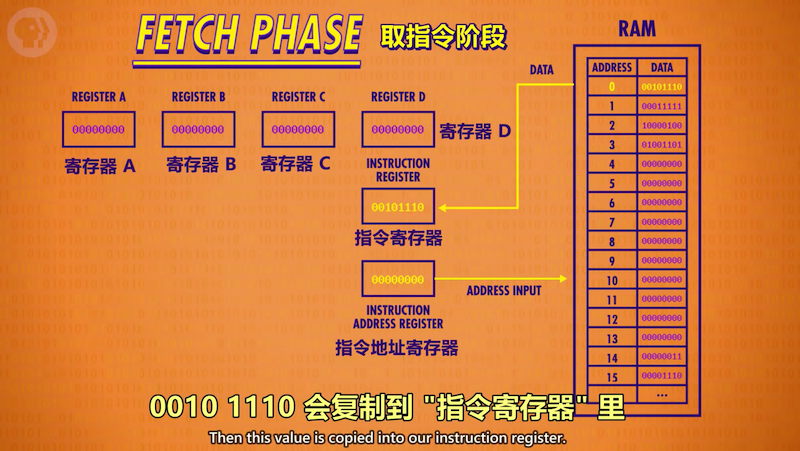
程序是一条条指令组成的;内存中既可以存放数据,也可以存放指令。

指令表:前4位是操作码,后4位是内存地址或寄存器,表示数据来自哪里。
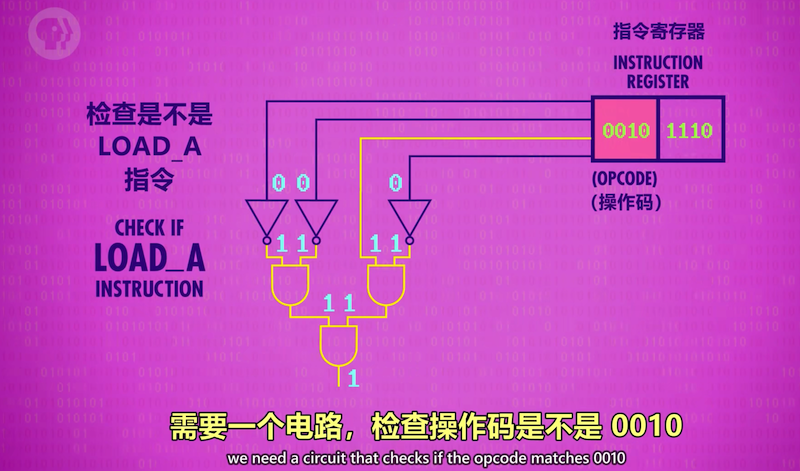
解码阶段(Decode Phase):指令由控制单元内的逻辑电路进行解码
执行:把检查指令的电路输出连到RAM的RE线,把指令后4位发送到地址线,读出数据到寄存器A
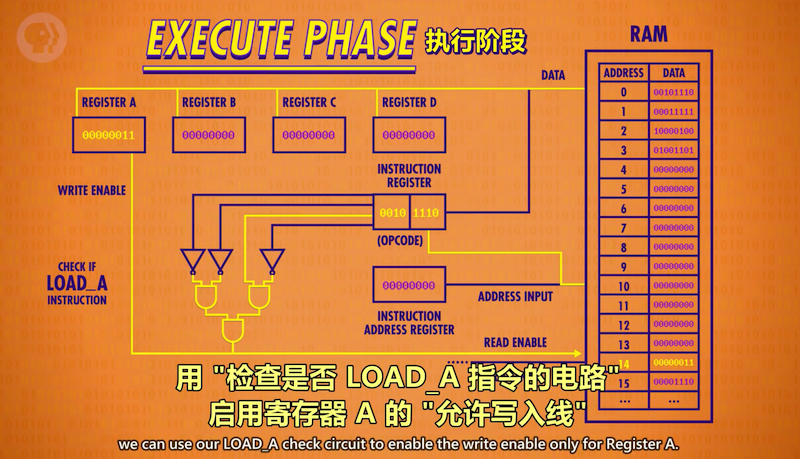
加载数据到A后指令完成,关闭所有线路,准备取下一条指令;IAR+1, 执行阶段就此结束。
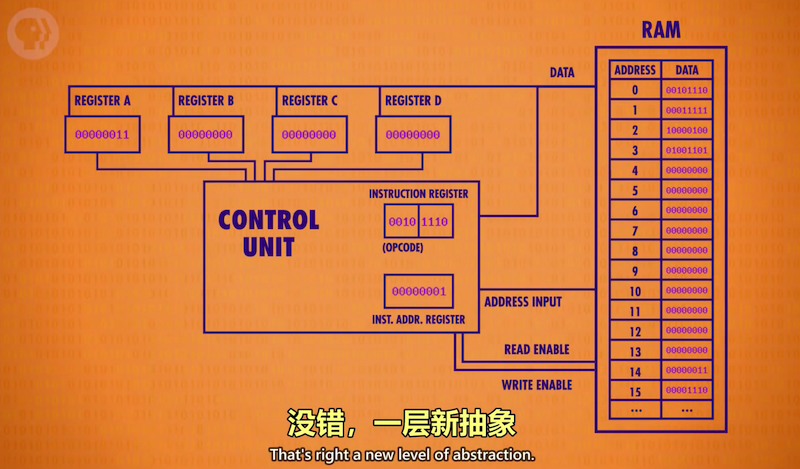
由于解码电路太繁琐,进一步抽象控制单元:
ADD B, A指令: B + A → TR → A
相加的结果不能直接写入寄存器A, 因为A连着ALU的输入,会导致新的sum不断进入ALU相加形成死循环;
需要一个临时寄存器TR保存相加的结果,关闭ALU, 然后把TR的值写入目标寄存器A
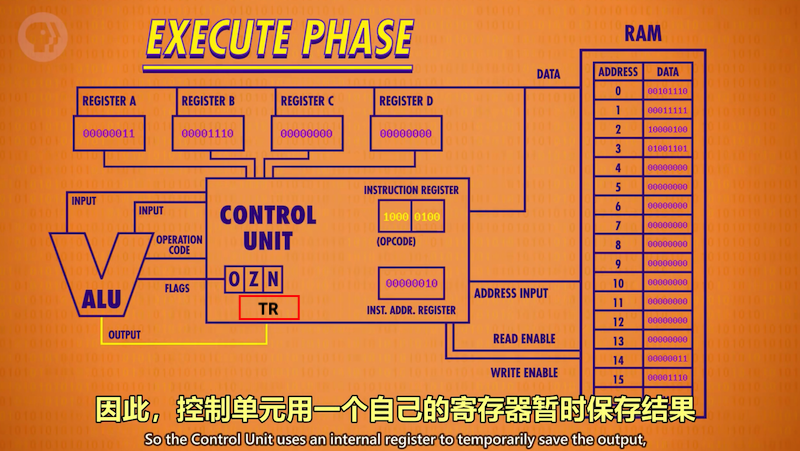
STORE A 1101 指令:把地址1101传给RAM, 打开WE线,同时打开寄存器A的RE线
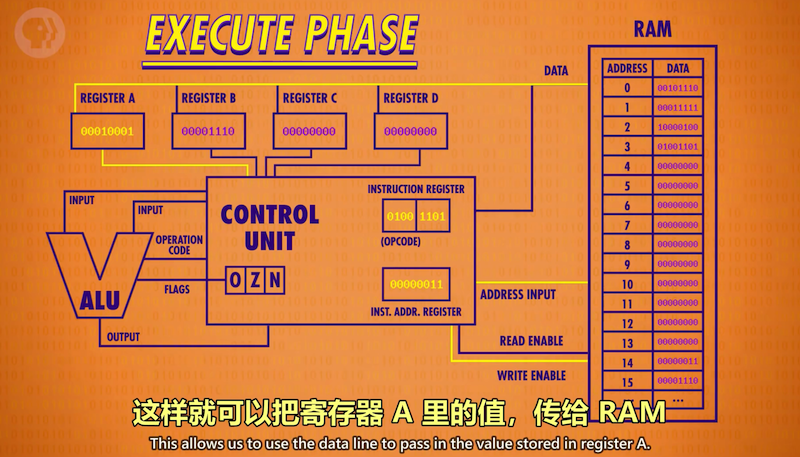
CPU需要一个时钟来自动切换“取指-解码-执行”的各个阶段,
使CPU按照指令周期的时序方式来工作(tick along)
时钟以精准的间隔触发电信号,控制单元利用时钟信号来推进CPU的内部操作,使一切保持同步进行
时钟的比喻:罗马帆船的船头负责按节奏击鼓的人,像节拍器一样使所有划船的人动作同步
Clock Speed 时钟速度又叫时钟频率: CPU“取指-解码-执行”的速度,单位是Hz,1Hz即1秒1次 (1个指令周期)
1971年第一个单芯片CPU英特尔4004 每秒740k赫兹,即每秒74万次 (74万个指令周期)
现代的计算机时钟频率能达到几G赫兹 (giga Hz = 几千兆Hz = 几十亿Hz) 即每秒10亿个以上的时钟周期
超频 overclocking:意思就是修改时钟频率,加快CPU速度 (比喻: 罗马船头加快击鼓)
芯片制造商经常给CPU留一点余地,可以接受一点超频,但超频太多会让CPU过热或产生乱码,因为信号跟不上时钟
降频 underclocking 有时没必要让CPU全速运行,可能用户走开了或者在跑一个性能要求较低的程序,降频可以省电
省电对使用电池的设备很重要,比如笔记本电脑和手机,很多现代处理器可以按需加快或减慢时钟速度,称为
动态频率调整Dynamic Frequency Scaling
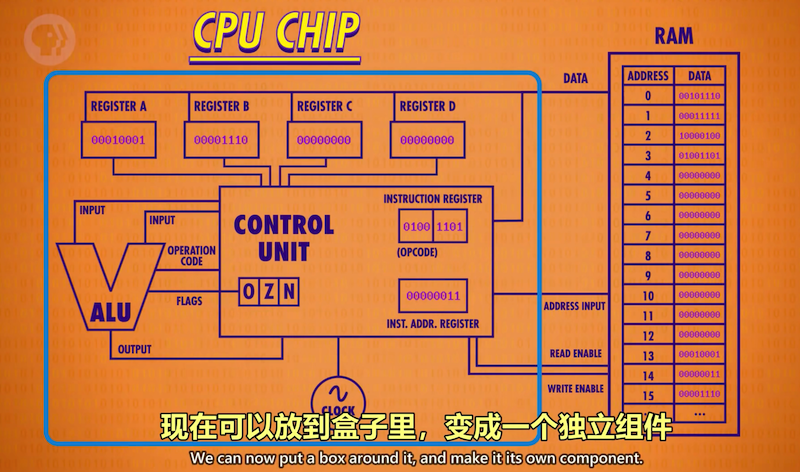
8 指令和程序 (Instructions & Programs)
CPU之所以强大,因为它是可编程的,如果写入不同序列的指令就会执行不同的任务。
CPU is a piece of hardware controlled by easy-to-mofidy software.
添加JUMP和条件JUMP实现循环 SUB B A := A - B → A
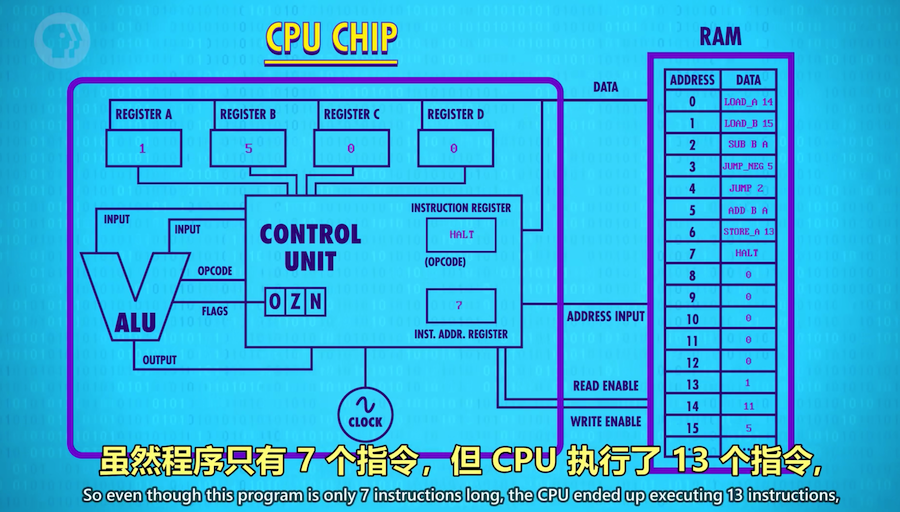
这实际上是一个计算余数(11 mod 5)的除法程序, 如果多加几行指令,还可以跟踪循环了多少次,得到商 = 2
这段代码对任意两个数都成立,这就是软件的强大之处,让我们做到了硬件做不到的事。例子中的ALU并没有
除法功能,是程序给了这个功能,其他的程序也可以调用这段除法程序来做其他事情,这又是一层新的抽象。
9 高级CPU设计 (Advanced CPU Designs)
现代处理器有专门的电路来处理图形操作、解码压缩视频、加密文件等,如果用标准操作来实现要很多时钟周期
SIMD全称Single Instruction Multiple Data,单指令多数据流。以加法指令为例,单指令单数据(SISD)CPU对加法指令译码后,执行部件先访问内存取得第一个操作数;之后再一次访问内存取得第二个操作数;随后才能进行求和运算。而在SIMD型的CPU中,指令译码后几个执行部件同时访问内存,一次性获得所有操作数进行运算。这个特点使SIMD特别适合于多媒体应用等数据密集型运算。
MMX: MultiMedia eXtensions(多媒体扩展)的缩写,1996年Intel公司推出。MMX技术是在CPU中加入了特地为视频信号(Video Signal)、音频信号(Audio Signal)以及图像处理(Graphical Manipulation)而设计的57条指令。
3DNow! 指令集: 1998年AMD开发的一种3D加速指令集,支持单精度浮点数的矢量运算,包含21条指令,用于增强x86架构计算机在三维图像处理上的性能。
SSE(Streaming SIMD Extensions)是英特尔在AMD的3D Now!发布一年之后在Pentium III中引入的指令集,是继MMX的扩展指令集。SSE指令集提供了70条新指令。AMD后来在Athlon XP中加入了对这个新指令集的支持。
第一个集成CPU英特尔4004只有46条指令,而现代处理器有上千条指令,使用各种巧妙复杂的电路。
超高的时钟速度带来一个问题:如何快速传递数据给CPU? 就像有强大的蒸汽机,但无法快速加煤。RAM成了瓶颈,RAM是CPU之外的独立部件,数据要通过总线(Bus)来传输,尽管总线可能只有几厘米,电信号接近光速,但CPU每秒要处理上亿条指令(GHz), 很小的延迟也会造成问题,RAM还需要时间查地址,取数,配置输出,所以一条从内存读数据的load指令可能要花多个时钟周期,此时CPU空转等待数据,解决方法之一是给CPU加一点SRAM,即缓存(Cache)通常只有KB和MB。
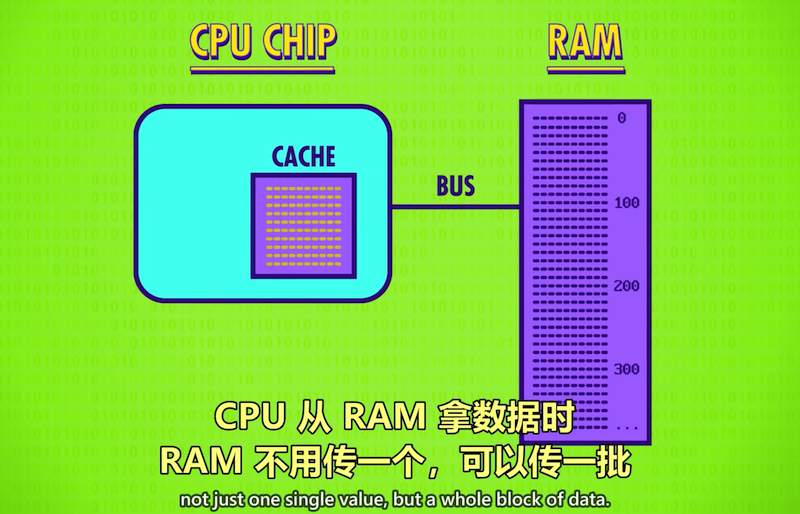
缓存(Cache)
程序的局部性:实际应用中数据通常在空间上连续存放,程序按顺序处理。
把数据块复制到Cache中,离CPU很近,取下一条数据时发现已在Cache中,
不用反复访问RAM, 一个时钟周期就能给数据,CPU不用空等。
如果请求的数据已在缓存中,称为缓存命中(Cache Hit) 不在缓存称为Cache Miss
缓存也可以当作临时空间 (Scratch Space) 为较长较复杂的运算存一些中间值。
例如CPU算完了一天的销售额,可以先把结果存在Cache, 不但存起来快一些,如果要取值也快一些。
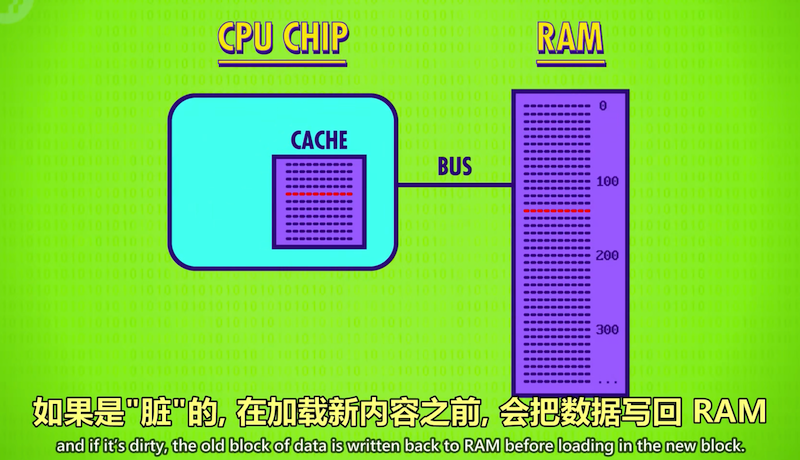
这带来一个新的问题:缓存的copy和RAM的数据不一致了。这种不一致mismatch必须记录下来,之后要同步。
因此Cache中的每块空间都有一个特殊标记(flag) , 叫做脏位(Dirty Bit)。
同步经常发生在缓存已满而CPU又请求一块新内存的时候。在清除旧缓存腾出空间之前,会先检查脏位:
流水线设计(Pipeline)
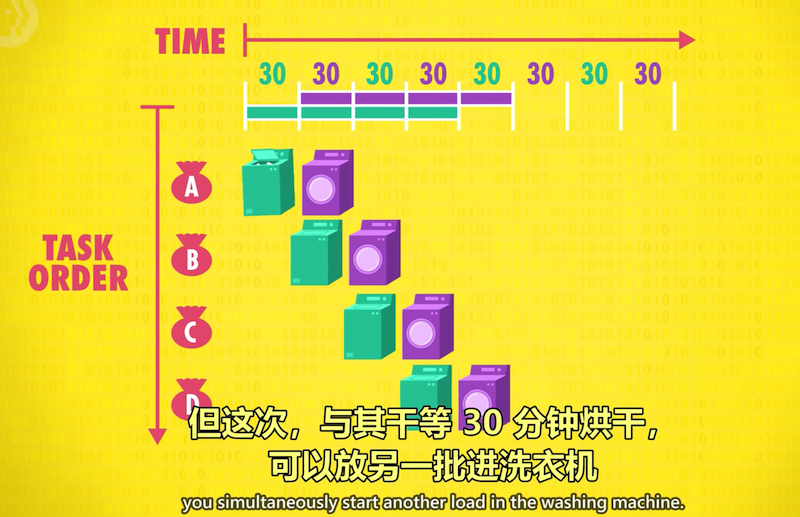
酒店洗床单的例子:1台洗衣机和1台干燥机,
利用“并行处理”提高效率(parallelize your operation):吞吐量 x 2
一个任务的不同阶段由不同部件完成,
当一个任务进入下个阶段时,上个阶段的部件不再空转,而是用来执行下一个任务的相应阶段
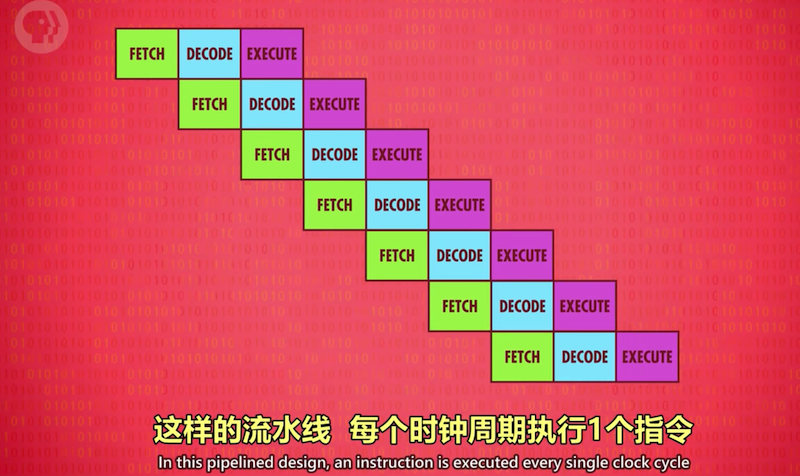
CPU指令处理也可采用流水线,之前按序执行1条指令需3个时钟周期。
“取指-解码-执行”三个阶段由不同部件完成,意味着可以并行处理parallelize:
execute一条指令的同时decode下一条指令,再下条则可以开始取指。任一时刻CPU所有部件都没有空转。
每个时钟周期都能完成原本1条指令的工作量,吞吐量 X 3, 流水线过程中,每过1个时钟周期就有一条指令执行完成。
流水线的并行方式也会带来一些问题。首先是指令之间的依赖关系
举个例子,按照指令的顺序,有一条指令需要读取前一条指令修改后的数据,但因为流水线的安排,
前一条指令还没开始修改(刚完成解码阶段)这条指令就已经在读取修改前的数据,也就是说读到的是旧数据!
因此流水线处理器要提前弄清(look ahead) 数据的依赖性,必要时停止流水线(stall pipelines),避免出现错误
高端CPU, 手机和笔记本里那种,会更进一步,动态重排序 (dynamically reorder)有依赖关系的指令,
以最小化流水线的停工时间(minimize stalls and keep the pipeline moving)
这叫做“乱序执行”(out-of-order execution)
比如例子中改数据的指令可以适当往前排以避开冲突,保证后面能读到修改好的数据。
实现的电路非常复杂,但因为非常高效,几乎所有现代处理器都有流水线。
第二问题是“条件跳转”(conditional jump) 例如上节的JUMP NEGATIVE,
条件jump指令会根据实际的条件值改变程序的固定执行流,
简单的流水线处理器看到条件jump指令会先停一会儿,等待条件值确定下来 ,jump结果出了再继续流水线,但这样会增加延迟,高端cpu会采用一些技巧来减少线的停工时间。
Imagine an upcoming jump instruction as a fork in the road - a branch.
可以把jump指令想象成岔路口,即分支,高端CPU会猜哪条分支的可能性大一些,
然后提前把该分支的指令放进流水线,这种技巧叫做“预测执行”(speculative execution)
jump结果出来如果CPU猜对了,那流水线已塞满正确的指令,可以毫无延迟地马上运行;
如果猜错了就清空流水线(pipeline flush)就像走错路掉头回到正轨一样。
为了尽可能减少清空流水线的次数,CPU厂商开发了复杂的方法
来预测哪条分支可能性更大,叫做“分支预测”(branch prediction) 现代CPU的预测正确率超过90%!
超标量 (superscalar)
理想情况下,流水线1个时钟周期能完成1条指令。然后超标量处理器(superscalar processors)出现了
一个时钟周期能完成多条指令。
即便有流水线设计,在指令执行阶段,处理器内有些区域还是可能会空闲。
例如执行一个从内存取值的指令期间,ALU会闲置。所以一次性处理(取指+解码)多条指令会更好,
如果多条指令刚好需要CPU的不同部件,那就多条同时执行。
可以再进一步,多加几个相同的电路来执行频次很高的指令。
例如很多处理器有4-8个甚至更多完全相同的ALU, 可以并行执行多个数学运算。
多核 (multi-core)
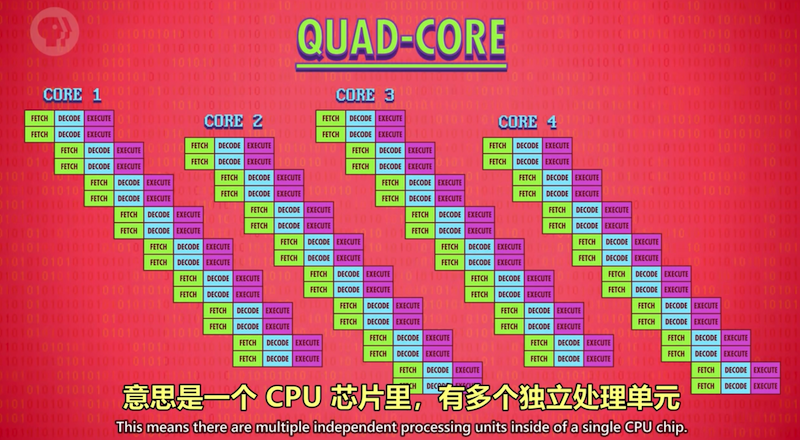
很像是有多个独立的CPU, 但因为它们紧密整合,可以共享一些资源,比如缓存,使得多核可以合作运算。
多核如果还不够,可以使用多CPU, 例如Youtube服务器这种高端计算机,需要更多马力让上百人能同时流畅观看视频。
2-4个CPU的服务器是最常见的。
超级计算机
堆砌CPU。更高的性能要求:如果需要做怪兽级的运算,比如模拟宇宙的形成,需要强大的算力。
世界上最快的计算机:神威-太湖之光,在中国无锡的国家超算中心

我们的使命是利用这些运算能力,去做又酷又实用的事。